16824 - Visual Learning and Recognition
Final Project
By: Adeep Biswas, Ishita Goyal, Sanjana Dulam (adeepb, igoyal, sdulam)
Website: https://ishita-cmu.github.io/

Virtual Clothing Try-On
USING GANs
MOTIVATION
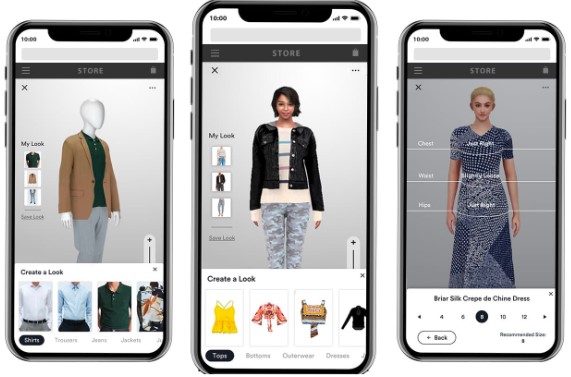
Why is it important and relevant? Why should we care? E-commerce has become one of the main go-to sources for clothes shopping these days with the advancement of the digital era. With the world being imposed with restrictions due to conditions like the pandemic, E-commerce has begun to flourish now more than ever. Although online shopping platforms bring retail to the comfort of your home, one of the main challenges that people face while buying clothes is that they’re not sure how the clothes would look on them once they try them on. In fact, this problem is not only faced by e-commerce customers but also by customers in physical stores. This can happen when they do not have the option of trying on clothes due to pandemic restrictions, for example.
Therefore, adding this as a feature to e-commerce websites would be very useful for customers as they would be able to make more informed purchase decisions. In addition, physical stores could also have virtual-try on facilities which would even help reduce waiting queues for fitting rooms and possibly assist customers who are in a hurry. This project would therefore help customers have a more satisfying shopping experience overall. Virtual try-on systems with arbitrary human poses have huge application potential but face several challenges such as dealing with varying clothes textures, self-occlusions and misalignment when dealing with different poses and so in our project, we aim to work towards making some contribution and improvement in this direction.
PRIOR WORK
Related works that are relevant to our idea.
With the recently increasing interest in virtual try-on systems bolstered by advancements in the research and applications of GANs, there is a substantial amount of work being done in this field. Xintong Han, Zuxuan Wu et al. worked on an image-based VIrtual Try-On Network (VITON) without using any 3D information. They aimed to transfer a desired clothing item onto the corresponding region of a person using a coarse-to-fine strategy. By conditioning upon a new clothing-agnostic yet descriptive person representation, they first generate a coarse synthesized image with the target clothing item overlaid on the same person in the same pose. They trained the network to learn how much detail to use from the target clothing item, and where to apply it to the person in order to synthesize a photo-realistic image in which the target item deforms naturally with clear visual patterns. With VITON, the authors were able to obtain a higher human evaluation score than state-of-the-art generative models and were able to output more photo-realistic virtual try-on effects. In a study [2] by Bochao Wang, Huabin Zheng, et al., the authors propose a fully-learnable Characteristic-Preserving Virtual Try-On Network (CP-VTON). The network learns a thin-plate spline transformation for transforming the clothes into fitting the body shape of the target person via a Geometric Matching Module (GMM). It works to alleviate boundary artifacts of warped clothes and make the results more realistic by learning a composition mask to integrate the warped clothes and the rendered image to ensure smoothness. The system was able to produce reasonable results with its alignment module while preserving the sharp and intact characteristics of clothes when compared to its baseline VITON model.
Haoye Dong, Xiaodan Liang, et al. in another study [3], make an attempt towards a Multi-pose Guided Virtual-Try On Network (MG-VTON) in which given an input person image, a desired clothes image, and a desired pose, it can generate a new person image after fitting the desired clothes onto the input image. Their system is constructed in three stages: 1) synthesis of target human parse map to match the desired pose and the desired clothes shape 2) warping of desired clothes onto the synthesized human parse map using a deep Warping Generative Adversarial Network (Warp-GAN) which helps alleviate the misalignment problem between the input human pose and desired human pose; 3) refinement rendering using multi-pose composition masks which recover the texture details of clothes and remove some artifacts. The MG-VTON was able to generate reasonable results with convincing details outperforming other baseline models such as VITON and CP-VITON.
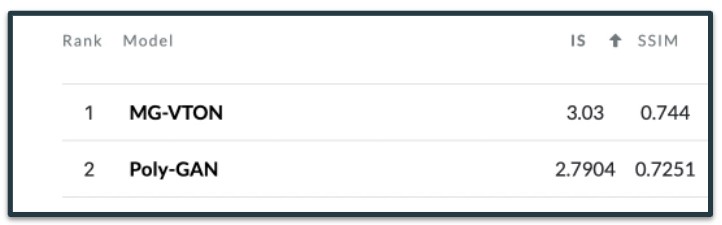
Nilesh Pandey and Andres Savakis present Poly-GAN in [4], a GAN architecture conditioned on multiple inputs. In contrast to previous systems which used different architectures in their three staged pipelines for fashion synthesis tasks, Poly-GAN used a common architecture for all three stages. It enforces the conditions at all layers of the encoder and utilizes skip connections from the coarse layers of the encoder to the respective layers of the decoder. The network is able to perform spatial transformations of the garment based on the RGB skeleton of the model at an arbitrary pose. Poly-GAN achieves state-of-the-art quantitative results on Structural Similarity Index metric and Inception Score metric using the DeepFashion dataset.
OUR IDEA
The idea of this project is to facilitate customers to try-on clothes virtually to see if they like how they look in the chosen clothes and in turn make more informed purchase decisions with an overall improved shopping experience. In order to achieve this, the system is designed such that given an input person image and a desired clothing article image, the model combines the image of the clothing article with the image of the customer in their corresponding pose to generate a new image of the user wearing the selected clothing item.
As mentioned earlier, virtual try-on systems with arbitrary human poses face several challenges such as segmentation, in-stitching and misalignment when dealing with different poses and so this project aims to work towards making some contribution in this direction by exploring new methodologies and making improvements upon existing models.
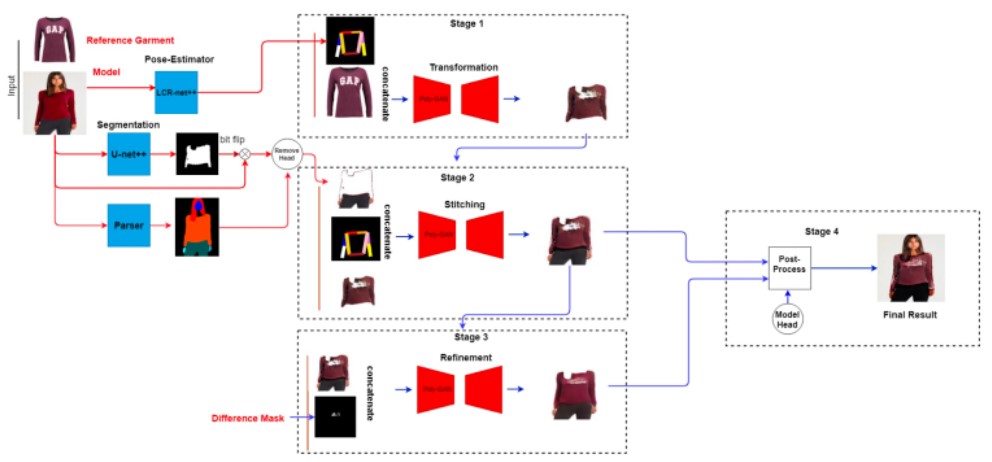
MG-VTON stands to be the state-of-the-art benchmark on the Deep Fashion Dataset. However, for the purpose of this project Poly-GAN was taken as the baseline model due to its greater flexibility and scope for improvement. Poly-GAN uses a common architecture for all three stages (pose-estimator and clothing shape transformation, stitching of desired clothes onto the human parse map, inpainting/refinement rendering). GANs by nature are very difficult and time consuming to train and so for the scope of this project, only stage 3 was taken as the point of focus to be experimented with.
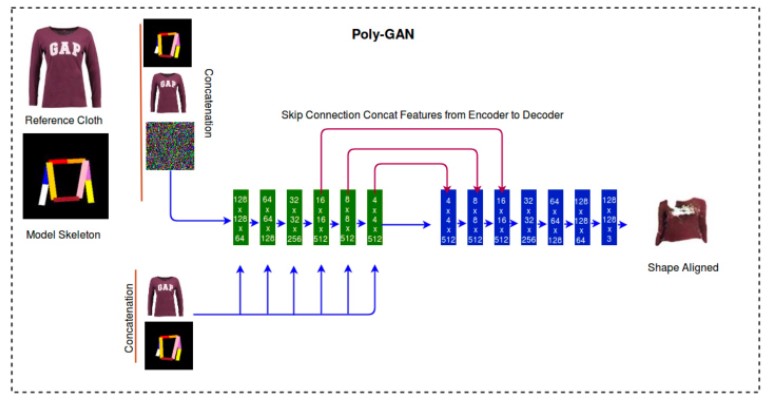
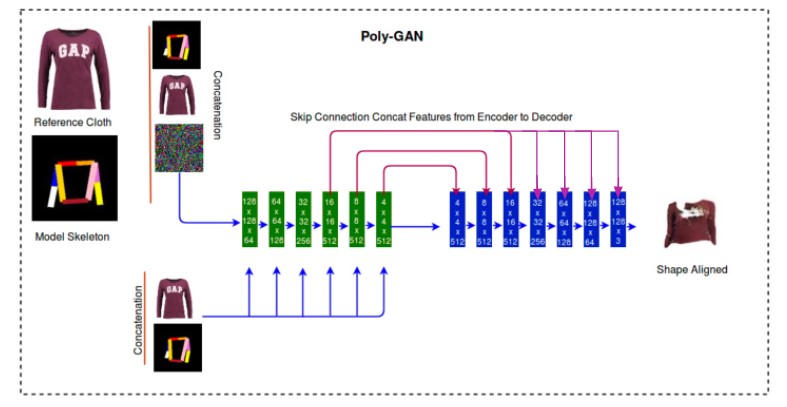
The first idea to be implemented was to add additional skip connections. The authors of the original paper initially tried to add skip connections between the encoder and decoder at spatial resolutions above (16x16) but found that it led to the generated image not being deformable enough to be close to the ground truth. If no skip connections above the spatial resolution of (16x16) were used, then the problem of missing minute details arises in the generated image. Using skip connection to connect all layers of the encoder to their respective decoder layers would help in passing minute details from the encoder side, but would also hinder learning and generating new images effectively. Therefore, building from their learning that a skip connection from a spatial resolution greater than 16x16 would pose a problem, skip connections were added from the 16x16 layer of the encoder to all the remaining subsequent layers of the decoder in order to help pass more minute information through the network. This extra information helped the model generate and decode better quality images without hindering the training process.

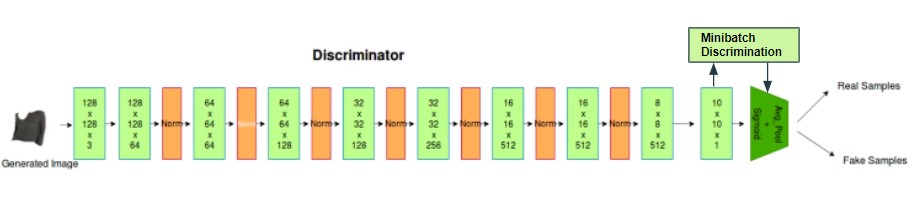
The second idea was to modify the architecture of the discriminator. The discriminator used in the original Poly-GAN architecture is the same as the discriminator used in the Super Resolution GAN Ledig et al. [5]. This was a novel architecture released back in 2017 since which several other contemporary state-of-the-art architectures and techniques have been created to improve the performance of GANs. Model collapse is a common issue faced during the training of GANs. When this happens, all the images created end up looking similar. In order to mitigate this problem, real images and generated images are fed into the discriminator separately in different batches and the similarity between image x and other images in the same batch is computed. The similarity o(x) is appended in one of the dense layers in the discriminator, in this case the final layer, to classify whether this image is real or generated. Minibatch discrimination helps generate visually appealing samples very quickly, and in therefore superior to techniques such as feature matching in this regard.
The third idea was to replace the ResNet module in the encoder with a vision transformer. This idea incepted from the fact that vision transformers have been found to incorporate more global information than ResNets at lower layers often leading to quantitatively different features. Furthermore, they tend to outperform CNN based architectures by a multiplicative factor in terms of both computational efficiency and accuracy. However, this proved to be infeasible as we later realized that a pre-trained transformer could not be used with the GAN since its generator takes in noise as input during training whereas the image distribution on which the transformer was trained would be quite different. Another option would’ve been to train the transformer from scratch which again proved infeasible due to the limitation of time and resources.
RESULTS

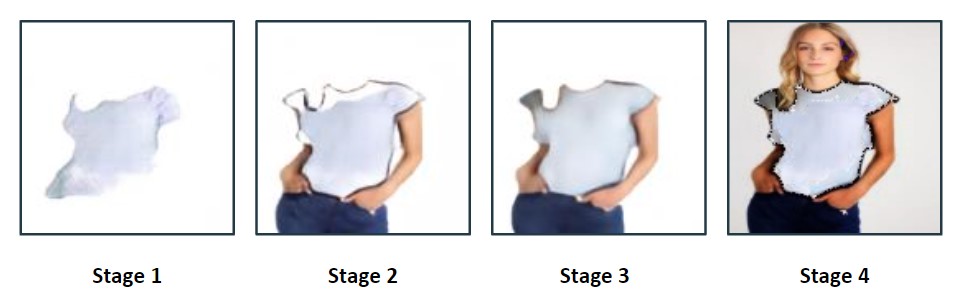
This is what the outputs generated from our model looks like
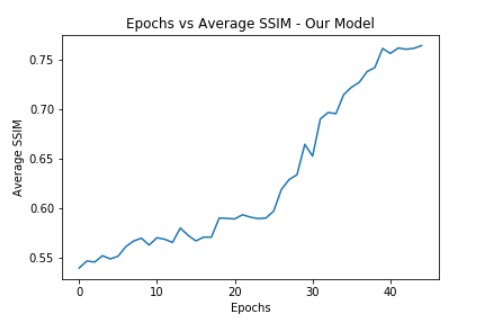
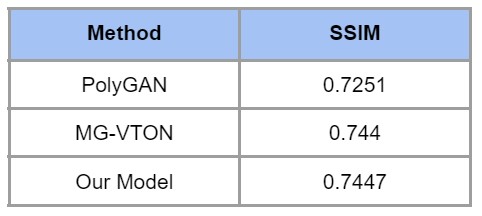
Our final model was able to achieve a SSIM value of 0.7447 which beat the SSIM score achieved by the original architecture at 0.7369 (for stage 3) as reported in the referenced research paper and is also equal to the MG-VTON architecture which has a SSIM score of 0.744 and is the current state-of-the-art model on DeepFashion dataset.
The second parameter for comparison used in the original paper was Inception Score. In our implementation after making the model changes, unfortunately we kept getting the inception score for all generated images as either 1.0 or ‘NaN’. We tried fixing the issue by using various different frameworks as well as writing our own code to compute the IS, however the issue continued to persist and we couldn’t get proper values unless we made changes in the formula of Inception score calculation itself because of the nature of values getting returned after passing our generated tensor through Inception-V3 model. Therefore, we have removed IS as a criteria of comparison between our model and the baseline model in the final results.
Lastly, we had noticed that the UNet++ architecture used by the original pipeline for image segmentation as part of the original pre-processing had some drawbacks in the form of leaving out very apparent borders of the segmented region, which made the final output look bad. In order to overcome this, we tried using DeepLabV3+ pre-trained architecture as a replacement to UNet++ for better image segmentation. However, this experimentation failed as we did not achieve better results using this. One of the reasons that we can think of for this failure is that we were unable to fine-tune the DeepLabV3 pre-trained model properly which resulted in suboptimal results. Therefore,we stuck with UNet++ in the end.
SUMMARY AND CONCLUSION
In conclusion, we tried modifying various different components of the original GAN architecture that we chose. While some of our modifications did not end up working out as expected, we achieved our overall objective and our experiments were successful in improving the performance of the baseline PolyGAN model that we chose. However, the task of Virtual Try-On is largely still unsolved and we still have a long way to go to achieve more realistic results that can actually be used in an e-commerce application.
FUTURE DIRECTIONS
For future directions, we would like to fix the bug currently present in our inception score calculation. We would also like to explore the idea of applying color correction as a post-processing step in order to make the final output image quality better and more realistic since the images that get generated currently have a skin tone on the face that does not match with the rest of the body.
LINK TO CODE
Github Repository: https://github.com/ishita-cmu/ishita-cmu.github.io
REFERENCES
[1] VITON: An Image-based Virtual Try-on Network, Xintong Han, Zuxuan Wu, et al., https://arxiv.org/pdf/1711.08447v4.pdf
[2] Toward Characteristic-Preserving Image-based Virtual Try-On Network, Bochao Wang, Huabin Zheng, et al., https://arxiv.org/pdf/1807.07688.pdf
[3] Towards Multi-pose Guided Virtual Try-on Network, Haoye Dong , Xiaodan Liang, Bochao Wang, et al., https://arxiv.org/pdf/1902.11026v1.pdf
[4] Poly-GAN: Multi-Conditioned GAN for Fashion Synthesis, Nilesh Pandey, Andreas Savakis, https://arxiv.org/pdf/1909.02165v1.pdf
[5] Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., ... & Shi, W. (2017). Photo-Realistic Single Image Super-Resolution using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 4681-4690).
[6] https://towardsdatascience.com/gan-ways-to-improve-gan-performance-acf37f9f59b